应用层 ApplicationLayer Part Ⅰ
Principles of Network Applications
Section titled “Principles of Network Applications”Network application architecture
Section titled “Network application architecture”现代网络应用程序中所使用的两种主流体系结构:the client-server architecture 和 the peer-to-peer (P2P) architecture.
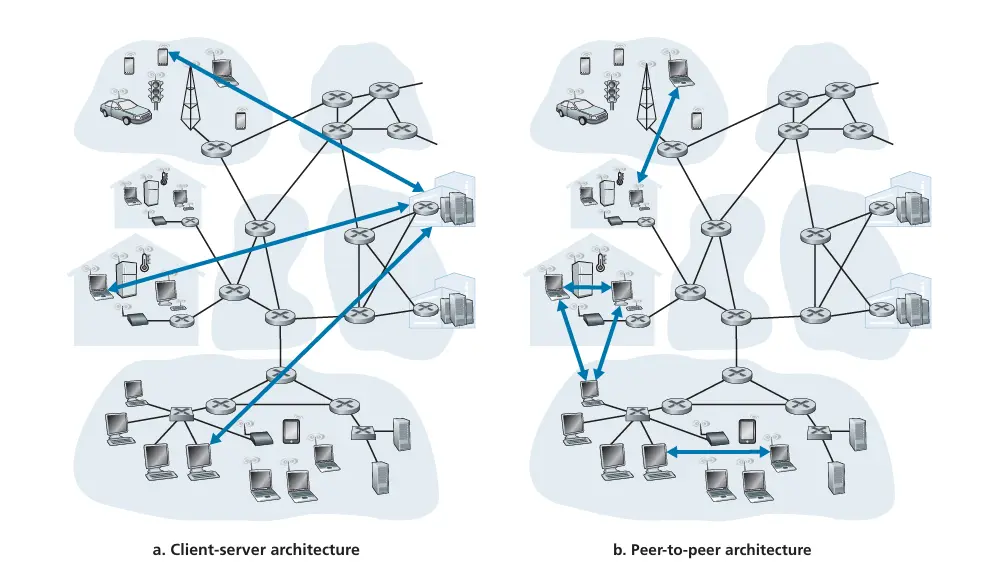
-
Server
- 总是在线(always on host);
- 永久的 IP 地址(permanent IP address);
- 配置在数据中心(often in data centers);
-
Client
- 与服务器沟通联系;
- 被间歇性(intermittently)的连接;
- 拥有动态地址;
- 客户之间不直接联系;
- 没有总是打开的服务器
- 任意一对主机(peer)直接相互通信
- 对等方间歇连接并且可以改变 IP 地址
- 自我可扩展性 self-scalability
在许多传统的CS模型中,所有的请求都会集中到几台服务器上,随着用户数量的增加,服务器可能会过载。然而在 P2P 网络中,每个节点都可以成为数据的提供者和消费者,因此负载可以在所有的节点上进行分布,使得网络能够更好地扩展。 然而,这并不意味着 P2P 网络没有扩展性问题。例如,当网络规模变得非常大时,查找和路由可能会变得复杂和昂贵。因此,需要使用高效的查找和路由算法,例如分布式哈希表(DHT),来确保网络的可扩展性。
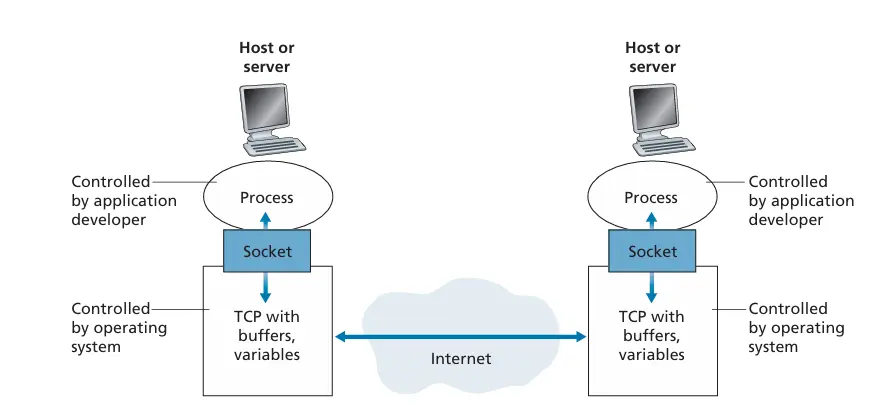
Processes Communicating
Section titled “Processes Communicating”两个进程可通过网络发送报文来完成通信,使用 IP 地址和端口号来标识进程
- Socket: 为应用程序与网络之间提供了数据交互的 API,如建立连接、发送和接收数据等
- ID Address: 用于唯一标识 Internet 中的主机
- Port: 用于标识主机上的特定进程,如 80 端口用于 HTTP 服务,25 端口用于 SMTP 服务等
Application Layer Protocols
Section titled “Application Layer Protocols”应用层协议(Application Layer Protocols)定义了在不同端系统上运行的应用程序进程如何相互传递消息:
- 交换的消息类型,例如,请求消息和响应消息
- 报文类型的语法:报文中的各个字段及其详细描述
- 字段的语义,即包含在字段中的信息的含义
- 进程何时、如何发送报文及对报文进行响应
应用层协议根据其是否公开可供所有人使用,可以分为两种类型:公共协议和专用协议:
- 公共协议:由 RFC 文档定义,可供所有人使用,例如 HTTP,SMTP,POP3
- 专用协议:由公司或组织定义,例如 Skype, KaZaA
The Web and HTTP
Section titled “The Web and HTTP”Overview of HTTP
Section titled “Overview of HTTP”- 网页 WebPage,或称 Document由许多对象 Object组成。
- 对象就是文件,可以是 HTML 文件, JPEG 图像, Java applet, 音频文件…
- 多数网页由单个基本 HTML 文件 base HTML和若干个所引用的对象构成
- 每个对象被一个 统一资源定位符 URL Uniform Resource Locator寻址
- **Web 浏览器(Web browser)**实现了 HTTP 的客户端;**Web 服务器(Web server)**实现了 HTTP 的服务器端;
- HTTP 使用 TCP 作为运输协议;
- HTTP 超文本传输协议(HyperText Transfer Protocol)
- 因为 HTTP 服务器不维护客户先前的状态信息, 是无状态协议(stateless protocol);
维护状态的协议非常复杂
- 必须维护过去历史 (状态信息)
- 如果 server/client 崩溃, 它们各自的状态视图可能不一致, 因此必须保持协调一致。
http://www.someschool.edu/someDept/pic.gif👆🏻协议 👆🏻主机名 👆🏻路径名www.example.com之后都发生了什么- DNS 解析过程
- 浏览器缓存:浏览器首先检查是否有该域名的缓存记录。
- 系统缓存:如果没有在浏览器缓存中找到,系统会检查操作系统的 DNS 缓存。
- hosts 文件:如果系统缓存中也没有记录,系统会检查 hosts 文件。
- 路由器缓存:如果 hosts 文件中没有记录,请求会被发送到本地网络的路由器,路由器也会检查其缓存。
- 递归搜索根域名服务器:如果以上步骤都没有找到记录,路由器会向根域名服务器发起递归查询,最终获取到 IP 地址。
- 建立 TCP/IP 连接(三次握手)
- 第一次握手:客户端发送一个 SYN(同步)包到服务器,并进入 SYN_SEND 状态,等待服务器确认。
- 第二次握手:服务器收到 SYN 包后,发送一个 SYN+ACK(同步+确认)包作为响应,并进入 SYN_RECV 状态。
- 第三次握手:客户端收到 SYN+ACK 包后,发送一个 ACK(确认)包,并进入 ESTABLISHED 状态,此时连接建立完成。
- 发送 HTTP 请求
- 由浏览器发送一个 HTTP 请求:客户端通过已建立的 TCP 连接发送 HTTP 请求到服务器。
- 经过路由器的转发:请求通过多个路由器进行转发。
- 通过服务器的防火墙:请求到达服务器前需要通过服务器的防火墙,防火墙会检查请求是否符合安全规则。
- 到达服务器:请求最终到达服务器。
- 服务器处理请求
- 服务器处理该 HTTP 请求:服务器解析请求并根据请求的内容进行处理。
- 返回一个 HTML 文件:服务器生成响应,通常是一个 HTML 文件,并通过 HTTP 响应发送回客户端。
- 浏览器解析和显示
- 浏览器解析该 HTML 文件:客户端浏览器接收服务器返回的 HTML 文件,并解析其中的内容。
- 显示在浏览器端:浏览器根据解析结果渲染页面,并显示在用户界面上。
User-Server Interaction: Cookies
Section titled “User-Server Interaction: Cookies”前面提到 HTTP 服务器为无状态的,而一个 Web 站点通常希望能够识别用户,可能是因为服务器希望限制用户的访问,或者因为它希望把内容与用户身份联系起来。为此,HTTP 使用了 cookie(最初被称作 magic cookie)🍪 Magic_cookie
cookie technology has four components:
- a cookie header line in the HTTP response message;
- a cookie header line in the HTTP request message;
- a cookie file kept on the user’s end system and managed by the user’s browser
- a back-end database at the Web site.
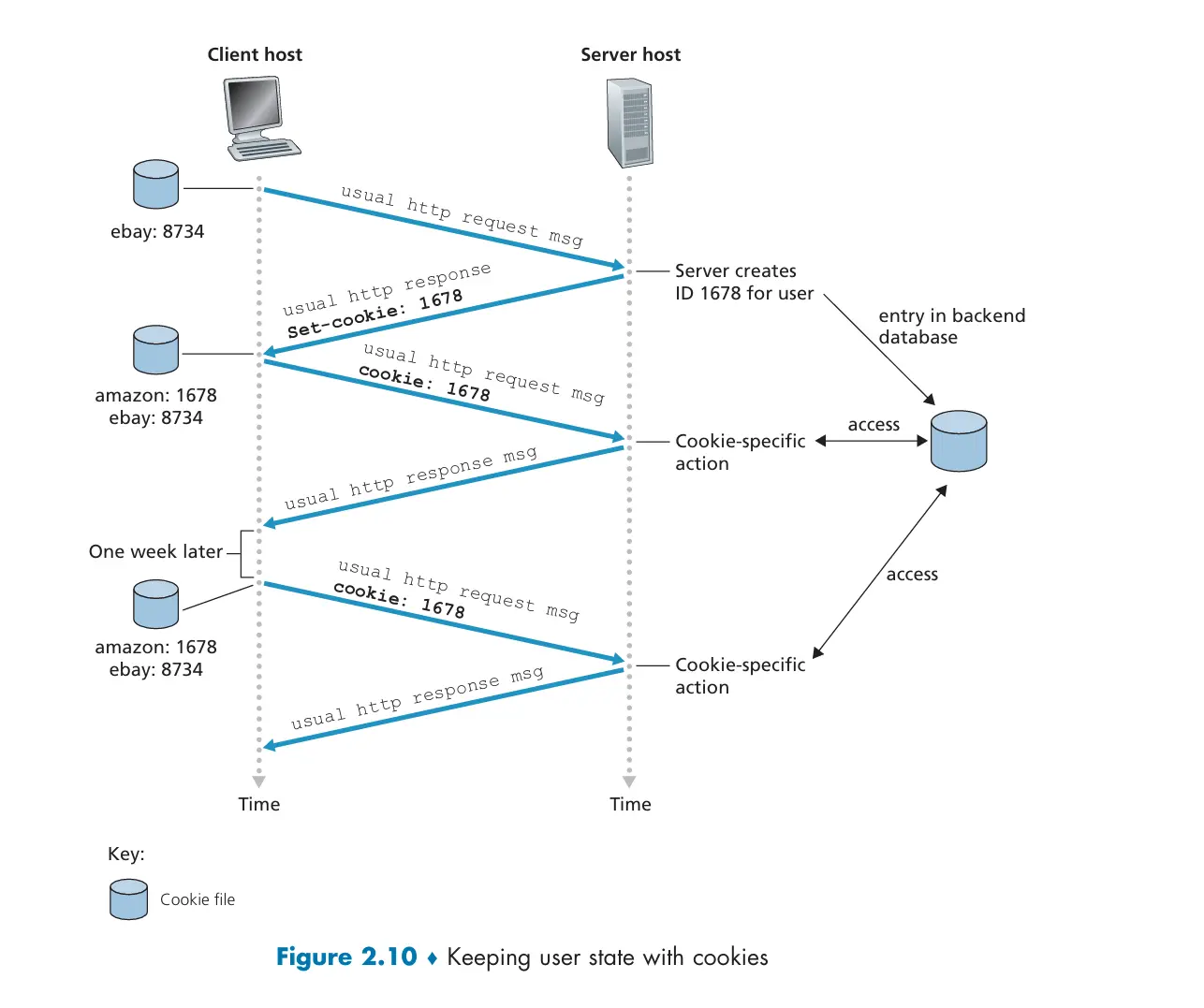
Cookies 跟踪用户 cookies 允许网站更加了解你 你可以提供名字和 e-mail 给网站 广告公司通过网站获得信息 Cookies 不适合游动用户 Cookie 可用于 跟踪用户在给定网站上的行为(第一方 cookie) 在多个网站上跟踪用户行为(第三方 cookie),而无需用户选择访问跟踪器网站! 跟踪可能对用户不可见:可能是一个不可见的链接 通过 Cookie 进行的第三方跟踪:在 Firefox、Safari 浏览器中默认禁用,将于 2023 年在 Chrome 浏览器中禁用
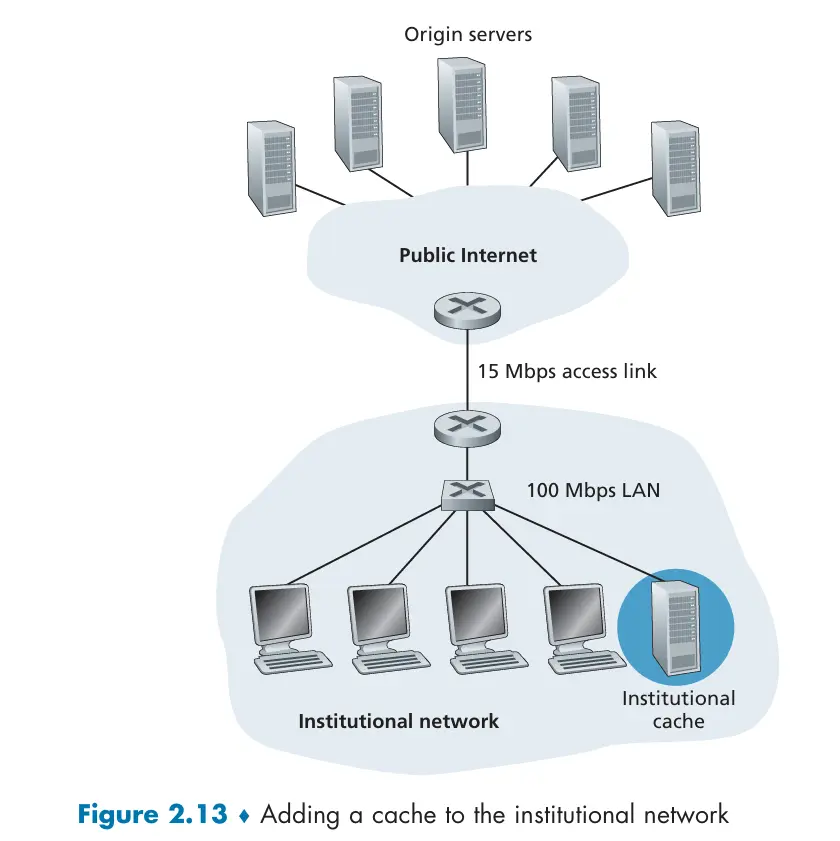
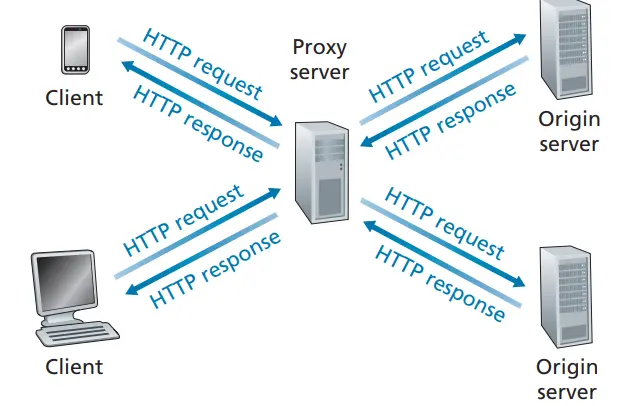
Web Caching(proxy server)
Section titled “Web Caching(proxy server)”Web 缓存器 Web cache,也称代理服务器 proxy server,设计它的目标是代表**初始 Web 服务器(origin server)**满足 HTTP 请求;一般的,Web 缓存器既是服务器又是客户机,典型的缓存器由 ISP 提供(大学、公司或居民 ISP);引入 Weh 缓存器减少了对客户机请求的响应时间,内部网络与接入链路上的通信量,并从整体上大大降低因特网上的 Web 流量
如图,加入 cache 后,客户端请求的对象可能在缓存器中(称作缓存命中),缓存器直接返回给客户端;图中接入链路(access link)的速率为 15Mbps,远低于局域网的网络速率,
,可见接入时延为该例中提升传播速率的瓶颈;可选择更快的接入链路,但这需要更多的费用;而缓存器可以减少接入链路上的流量,从而减少接入时延,同时费用相对较低 LAN delay: 在局域网中传输一个报文所需的时间 Access delay: 在两个路由器之间传输一个报文所需的时间 Internet delay: 在因特网中传输一个报文所需的时间
Request Steps:
- 浏览器创建一个到 Web 缓存器的 TCP 连接,并向 Web 缓存器中的对象发送一个 HTTP 请求;
- Web 缓存器进行检查,看看本地是否存储该对象副本。如果有,Web 缓存器向客户返回该对象;
- 如果缓存器中没有该对象,它就打开一个与该对象的初始服务器的 TCP 连接。Web 缓存器向初始服务器发送请求,并得到初始服务器的响应;
- 当 Web 缓存器接受对象后,在本地创建给对象的副本,并向客户发送响应报文返回该对象; 通过使用内容分发网络(Content Distribution Network,CDN),Web 缓存器正在因特网中发挥着越来越重要的作用。
尽管高速缓存器能减少用户感受到的响应时间,但引入了一个新的问题,即存放在缓存器中的副本可能陈旧的。为验证缓存器中的副本是否仍然有效,你可以使用条件 GET 请求
Electronic Mail in the Internet
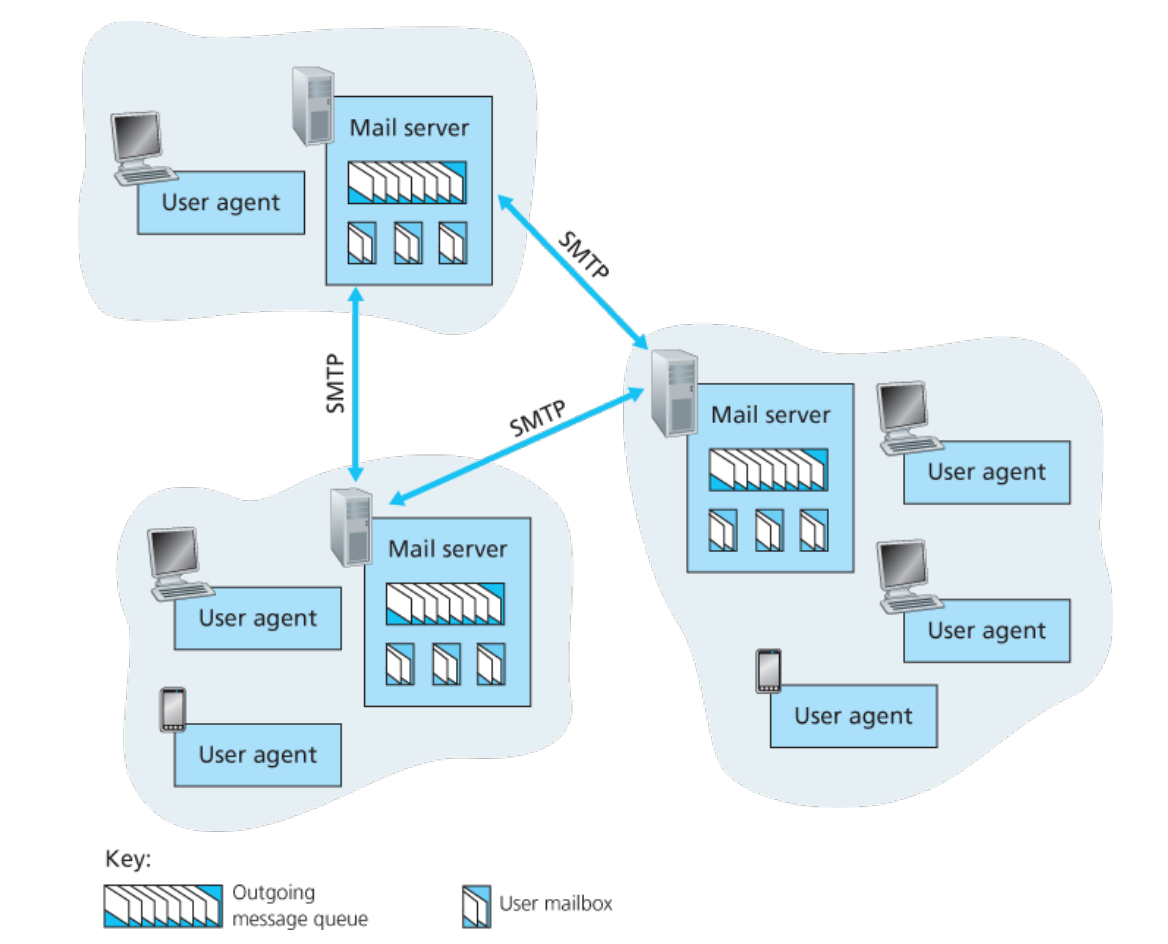
Section titled “Electronic Mail in the Internet”邮箱系统的 3 个主要组成部分:
- 用户代理 user agents
- 允许用户阅读,回复,转发,保存,编辑邮件;
- 服务器上存储的传入和传出的消息;
- 例如:Outlook, foxmail 等
- 邮件服务器 mail servers
- 邮箱(mailbox)包括用户传入的消息;
- 报文队列(message queue)中为待发送的邮件报文;
- 简单邮件传送协议 SMTP
SMTP 服务概述
Section titled “SMTP 服务概述”**SMTP(Simple Mail Transfer Protocol)**是一种用于电子邮件传输的标准协议。它定义了电子邮件客户端(如邮件程序)和邮件服务器之间的通信规则,以便可靠地将邮件从发送方传递到接收方。
- SMTP 使用持久连接
- SMTP 要求邮件消息(header & body)必须是 7-bit ASCII
- SMTP 服务器使用 CRLF.CRLF 来判断邮件消息的结束
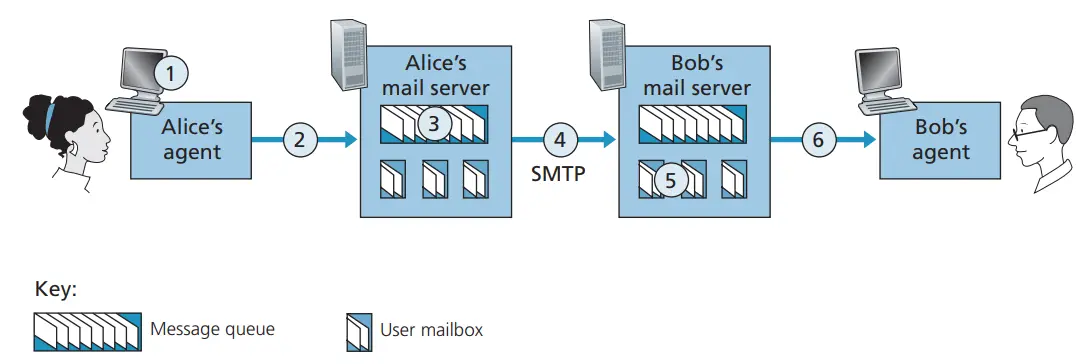
- 用户代理与发送服务器的连接:用户代理(例如电子邮件客户端)使用 SMTP 协议与发送服务器建立连接。连接过程包括身份验证和协议握手等步骤。 用户代理提交邮件: 用户代理将邮件发送到发送服务器。邮件的内容、收件人、发件人等信息被打包成一个 SMTP 消息。
- 发送服务器的邮件传递:发送服务器接收到用户代理提交的邮件后,开始根据收件人的电子邮件地址确定邮件的路由。它可能会通过 DNS 查找 MX 记录来找到目标邮件服务器,并将邮件转发给目标邮件服务器。
- 目标邮件服务器的接收与存储:目标邮件服务器接收到邮件后将其存储,并等待用户代理或接收器以后续协议(如 POP3 或 IMAP)请求获取邮件。
- 用户代理收取邮件:用户代理使用 POP3 或 IMAP 协议从接收服务器上下载邮件,并将邮件显示在用户界面上供用户查看和管理。
SMAP 与 HTTP 的区别
Section titled “SMAP 与 HTTP 的区别”| 特性 | SMTP | HTTP |
|---|---|---|
| 协议类型 | 推协议 push protocol | 拉协议 pull protocol |
| 数据编码 | 要求采用 7 比特 ASCII 码格式 | 不受 7 比特 ASCII 码限制 |
| 消息传递 | 发送文件的机器发起 TCP 连接 | 接收文件的机器发起 TCP 连接 |
| 报文封装 | 所有报文对象放在一个报文中 | 每个对象封装在不同的 HTTP 响应报文中 |
Mail Message Format
Section titled “Mail Message Format”一般格式如下:
To:发件人地址From:收件人地址Subject:邮件主题
...邮件正文MIME: Multipurpose Internet mail Extensions 多用途因特网邮件扩展, RFC 2045, 2046;增添额外的信头头部声明 MIME content-type,实现多媒体邮件
From: alice@crepes.frTo: bob@hamburger.eduSubject: Picture of yummy crepe.MIME-Version: 1.0Content-Transfer-Encoding: base64Content-Type: image/jpeg
base64 encoded data ....................................base64 encoded dataMail Access Protocols
Section titled “Mail Access Protocols”收件人的用户代理不能使用 SMTP 得到报文,因为取得报文是一个 pull 操作,而 SMTP 协议是一个 push 协议。通过引用一个特殊的邮件访问协议来解决这个问题,该协议将收件人邮件服务器上的报文传送给他的本地
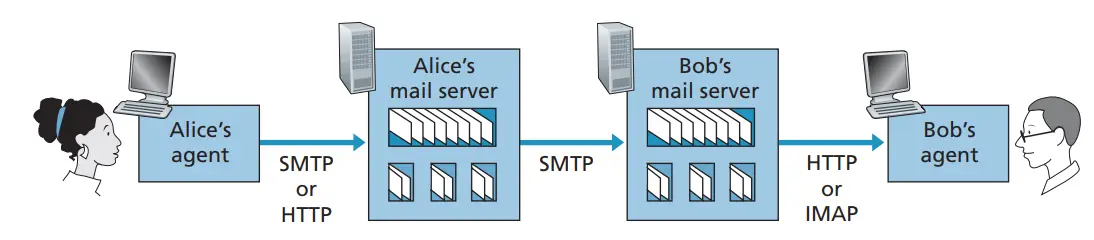
- SMTP: 递送/存储邮件消息到接收者邮件服务器
- 邮件访问协议: 从服务器获取邮件消息
- POP3: Post Office Protocol-Version3 邮局协议[RFC 1939]110 端口号
身份认证 (
代理 <-->服务器) 并 下载邮件消息 - IMAP: Internet Message Access Protocol [RFC 3501] 143 端口 更多功能特征,允许用户像对待本地邮箱那样操纵远程邮箱的邮件
- HTTP: Hotmail , Yahoo! Mail, etc.
- POP3: Post Office Protocol-Version3 邮局协议[RFC 1939]110 端口号
身份认证 (
POP3 VS IMAP
| 特性 | POP3 | IMAP |
|---|---|---|
| 邮件存储 | 下载邮件至本地客户端 | 在服务器上保留邮件副本 |
| 邮件同步 | 单设备上的邮件删除操作不会同步更新 | 多设备上的邮件操作同步更新 |
| 邮件管理 | 仅支持简单的邮件收发操作 | 支持复杂的邮件管理功能 |